






发布于:2022-03-23
本文总阅读量:





去哪儿网业务大规模容器化最佳实践
近几年随着云原生技术的成熟,Qunar 为了实现整个技术体系的演进,Qunar 在 2021 年向云原生迈出了第一步 -- 容器化 。 落地过程包括了价值评估、基础设施建设,CI/CD 流程改造、中间件的适配、可观测性工具、应用自动化迁移等。迁移过程涉及到了 3000 个应用左右,涉及千人级研发团队,是一个难度非常大的系统工程。这篇文章会讲述迁移过程涉及到的 CI/CD 模型改造、自动化应用容器化改造等最佳实践。
背景
容器化落地前的业务痛点
在容器化落地之前,我们经常会听到来自不同角色的各种各样的抱怨与吐槽:
- 领导层的声音:服务器资源和维护成本太高了,我们必须降低成本!
- OPS 的声音:有一台宿主故障了,需要把上边的服务赶快恢复!
- QA 的声音:测试环境好好的,为啥上线失败了?
- 研发人员的声音:业务高峰来啦,资源不够用啦!赶快去扩容!哎! 扩容太慢了。
造成这些问题的因素主要包含:资源利用率、服务无法自愈、测试环境与线上环境不一致,运行环境缺少弹性能力。
企业所面临的商业环境是复杂多变的,当今环境的竞争异常激烈,而且不再是大鱼吃小鱼,而是快鱼吃慢鱼。通用电气前 CEO Jack Welch 曾经说过:“如果外部变化的速度超过内部变化的速度,终结就不远了”。我们的企业如何能在这样的环境中存活发展呢?各个企业都在不断的探索和实践中前行。今年来,云原生技术日趋成熟,已经被广大企业广泛接受并采用。云原生技术可以帮助企业降低成本,加快业务迭代,对赋能企业的产业升级提供强有力的技术支撑。容器化作为云原生技术之一,成为 Qunar 拥抱云原生进行技术升级的重要一环。
容器化落地过程的挑战与应对
全司范围内进行容器化全面落地并不是一件容易的事,我们面临了重重困难,但是我们为了最终目标的达成,想尽一切办法去一一化解。
-
首先,涉及部门多: 容器化迁移涉及 OPS、基础架构、数据组等基础设施部门以及 20+业务部门。这么多的部门达成对目标的一致认同,并保持行动的协调一致是非常不容容易的。好在我们这个项目得到了公司高层的认可,并将此作为 2021 年的企业级目标。在企业级目标的引领下,各个部门协同一致,通力配合保障了项目的成功。
-
其次, 改造范围大:由于历史原因,我们的服务多是有状态的。从中间件、发布系统到网络、存储、日志收集、监控告警以及业务服务本身等等各个环节对机器名、IP、本地存储等状态有着强依赖。而容器本身是无状态的,这就意味着我们需要从基础设施、发布、运维的工具、平台进行整体改造。针对这重重问题,我们进行了一一列举,逐个击破,最终满足容器化迁移的条件。
-
再次,业务迁移成本高:本次迁移涉及应用数量大概有 3000 多个,迁移过程需要对应用进行升级改造、测试回归及上线,这个过程将花费大量人力。如何降低业务的迁移成本呢?我们支持将大部分的适配工作在中间件层进行统一支持,然后支持在业务代码中进行中间件的自动升级,自动进行容器化迁移,通过持续交付流水线对迁移过程中的变更进行自动化的测试与验证,经过容器与虚机灰度混部观察等手段大大降低了业务人工迁移的成本。
-
最后,学习成本高:我们的研发团队有千人级的规模,对于新技术的引入与升级,研发同学需要花费额外的成本进行学习和使用。为了降低大家的学习成本,我们通过平台工具屏蔽差异性操作以及技术细节,通过可视化配置、引导式操作,优化持续交付流程等方式来降低业务的学习成本。
容器化后的收益
经过 2021 年一年时间,我们完成了容器化基础设施建设,工具平台的升级改造以及 90% 应用的容器化迁移(应用总数 3000+)。从效果数据来看,容器化虚拟比例从 1:17 提升到 1:30, 资源利用率提升 76%;宿主运维时间之前以天为单位,容器化以后变成了分钟级,运维效率提升了 400 倍;由于容器化启动时间的缩短以及部署策略的优化,应用的交付速度提升 40%;K8s 集群提供了服务自愈能力,应用运行过程中平均自愈次数达到 2000 次/月;另外,容器化落地也为公司进行下一步云原生技术的深入推广与落地奠定了基础。
持续交付
项目研发流程
Qunar 采用了业务驱动的价值流与以应用为中心的持续交付工作流的双流模型。企业以业务价值交付为目标,在交付过程中,各个阶段的交付物会在多个角色中的流转,在流转过程中难免会出现不同程度的浪费。为了有效对价值交付的效率进行有效度量与优化提升,我们不仅仅需要关注开发过程中的效率提升,还需要关注开发前的效率提升。我们将持续交付工作流的流转与价值流的流动进行联通,希望可以实现从项目域、开发域、测试域到运维域的流程自动流转的。但是在容器化之前,由于环境不一致、各阶段配置的不一致性等原因,导致交付过程中,交付流程在各阶段间流转时不可避免的存在人工干预的情况。容器化之后,我们参照云原生的 OAM 模型,对应用进行了规范化定义,建立应用画像,统一术语,消除数据孤岛,使流程可以顺畅高速流转。
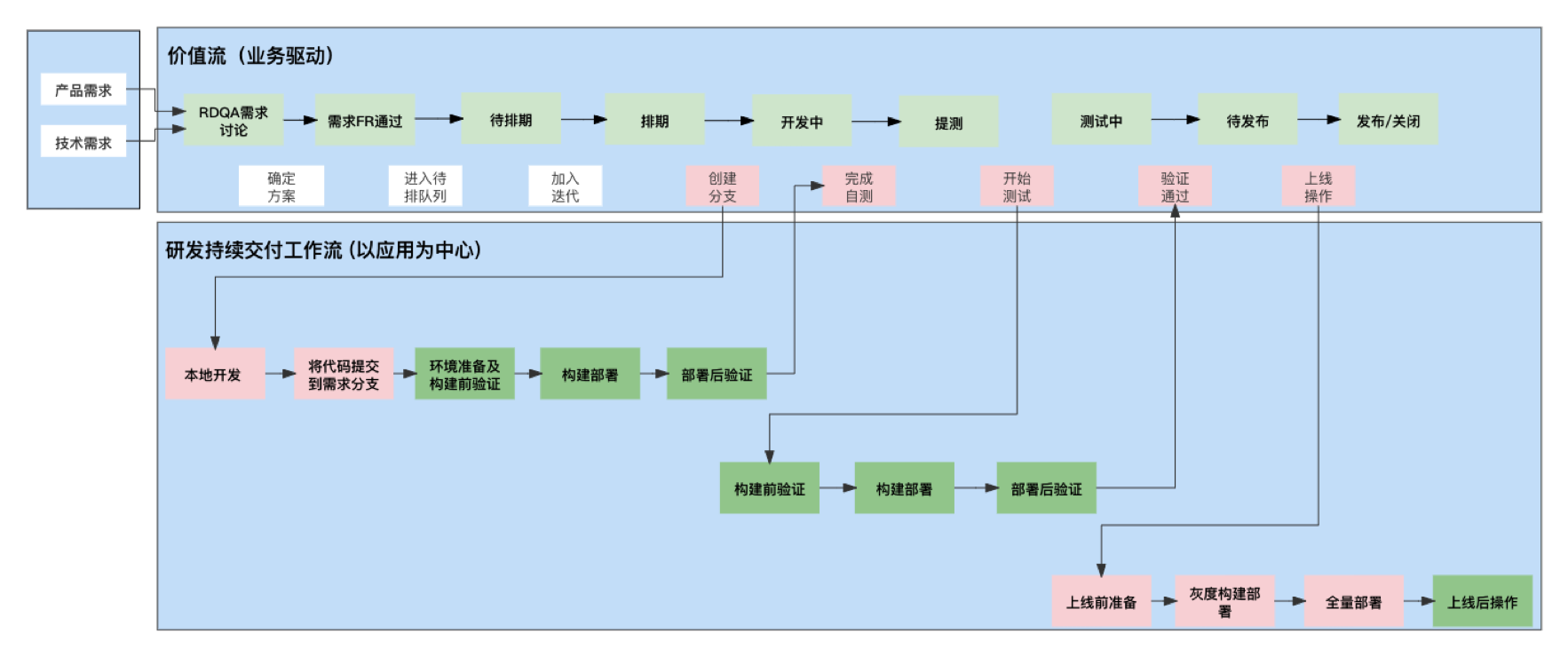
应用画像
针对上面项目的流程流转,最重要的一个连接器就是 App code, 因此我们也针对它做了抽象,画像定义:
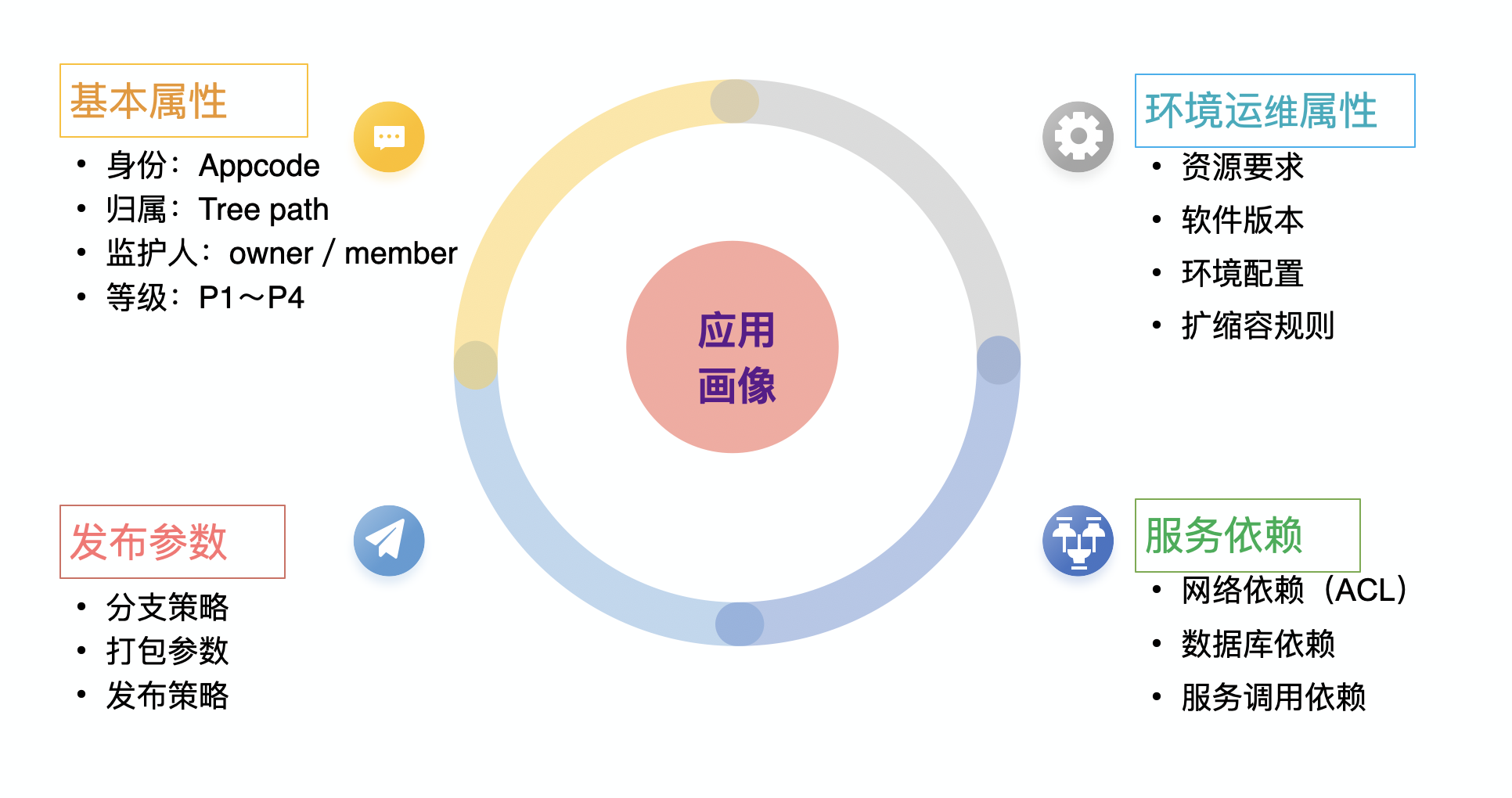
开发人员在面对开发、测试和生产等复杂的环境时、需要编写和维护多分应用部署配置文件;运维人员需要理解和对接不同的平台,管理差异巨大的运维能力和运维流程。
参照云原生中的开发应用模型原则,我们通过建立应用画像,指定应用的标准化定义。我们开发和运维人员通过标准的应用描述进行协作,轻松实现应用的“一键部署”、“模块化运维”,无须纠结于服务的开通配置和接入工作,提升应用交付与运维的效率和体验。
借助应用的规范化,将应用平台进行统一化与规范化。我们将原来的以资源为中心,转变为以应用为中心。平台架构如下:

多云协同
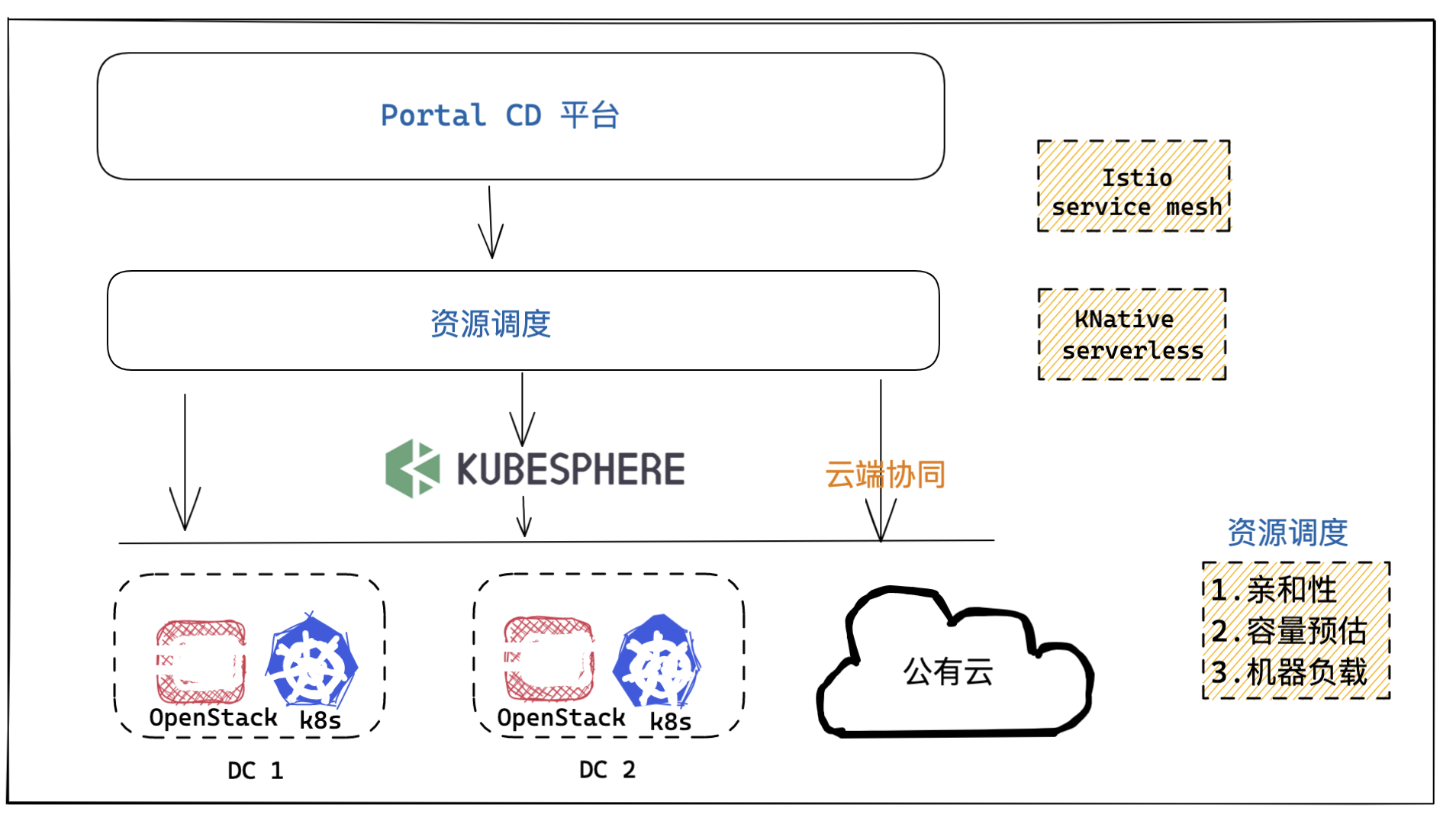
基础设施资源层: 底层资源既支持 KVM 也支持容器,这些资源都是跨机房部署。同时为了让底层资源更具弹性,我们对接了公有云。
平台层: 基于 K8s、KubeSphere 多集群管理、Service Mesh、Serverless 等云原生技术来提高技术先进性和技术的架构演进。
资源调度:
- 会考虑节点的亲和性: 机器配置, 普通磁盘、SSD, 千兆网卡、万兆网卡;
- 容量预估:发布前预计算, 如果资源不足,禁止发布;
- 机器负载:尽可能让集群所有节点负载均衡。
双 Deployment 发布
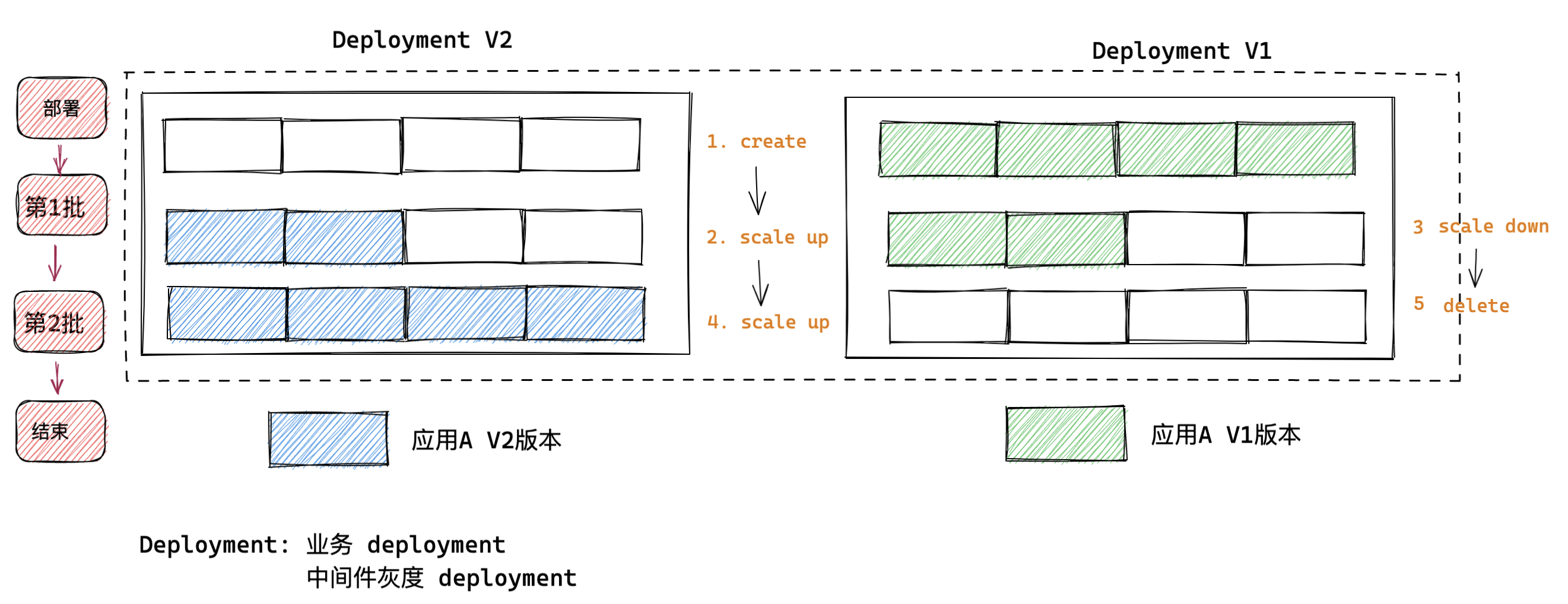
优点:
- 降低了操作复杂度, 操作只包含 create, scale, delete。 而单个 Deployment 更新过程可能会有更新过程失败,卡在中间状态, 升级和回滚都无法进行的时候;
- 支持分批操作, 发布流程更可控;
- 更新 Deployment label 变为可能。
缺点:
- 需要记录和控制 Deployment 状态,操作相对于单 Deployment 会相对复杂一些。
业务应用自动迁移方案
这次容器化需要迁移 3000+ 的应用,为了减少开发测试人员的迁移成本,我们提供了一个自动升级 Java SDK、自动迁移容器的方案。
自动迁移方案:

-
前置校验
- 验证是否引用了自动升级的 SDK;
- 编译阶段验证是否有不适合容器化场景使用的 Java 方法。 比如验证是否调用了依赖 hostname 的方法,如果有的化会提前提示容器发布失败。 因为容器场景 ip 变化是常态,hostname 也是经常变化的,过去业务线依赖 hostname 做业务逻辑区分的会有问题。
-
测试环境验证
自动升级 SDK 后在测试环境发布并验证应用的容器化升级是否 ok。
-
线上环境验证
- 灰度发布到线上,暂时不接入流量;
- 通知应用 owner 做自动化测试;
- 验证没问题,则接入线上流量。
-
混合部署
- 线上容器和 KVM 同时部署,流量比例根据实例比例调配;
- 关注指标与告警。
-
容器接入全部流量
容器全量部署,KVM 容量全部摘除 (KVM 会保留几天观察)。
-
观察
关注容器全量后的业务监控指标,如果发现异常及时迁回 KVM。
-
KVM 回收
为了快速腾出资源到 K8s 集群,我们会在规定期限内通知应用的 owner 回收机器, 如果超过规定时间(7 天),遗留的 KVM 资源回被强制回收。
自动升级 SDK 流程
tcdev bom 是公司统一管理二方包和三方包依赖的公共基础组建,绝大多数的 Java 应用都会使用这个组建,因此我们的升级 SDK 方案就是在编译过程自动检测并升级 tcdev 版本。
升级 SDK 的前置条件
| 前提 | 说明 |
|---|---|
| 二方包、三方包统一管理 | Super POM, tcdev-bom: 核心组件统一管理、升级 |
| 质量门禁 | 静态代码检查, 版本兼容性校验, 做好上线前的质量控制 |
| 自动验证组件升级后的兼容性 | 通过批量跑自动化测试,对比 master 分支和升级后的分支 |
| 发布的超管权限 | 自动升级、灰度、上线 |
升级步骤
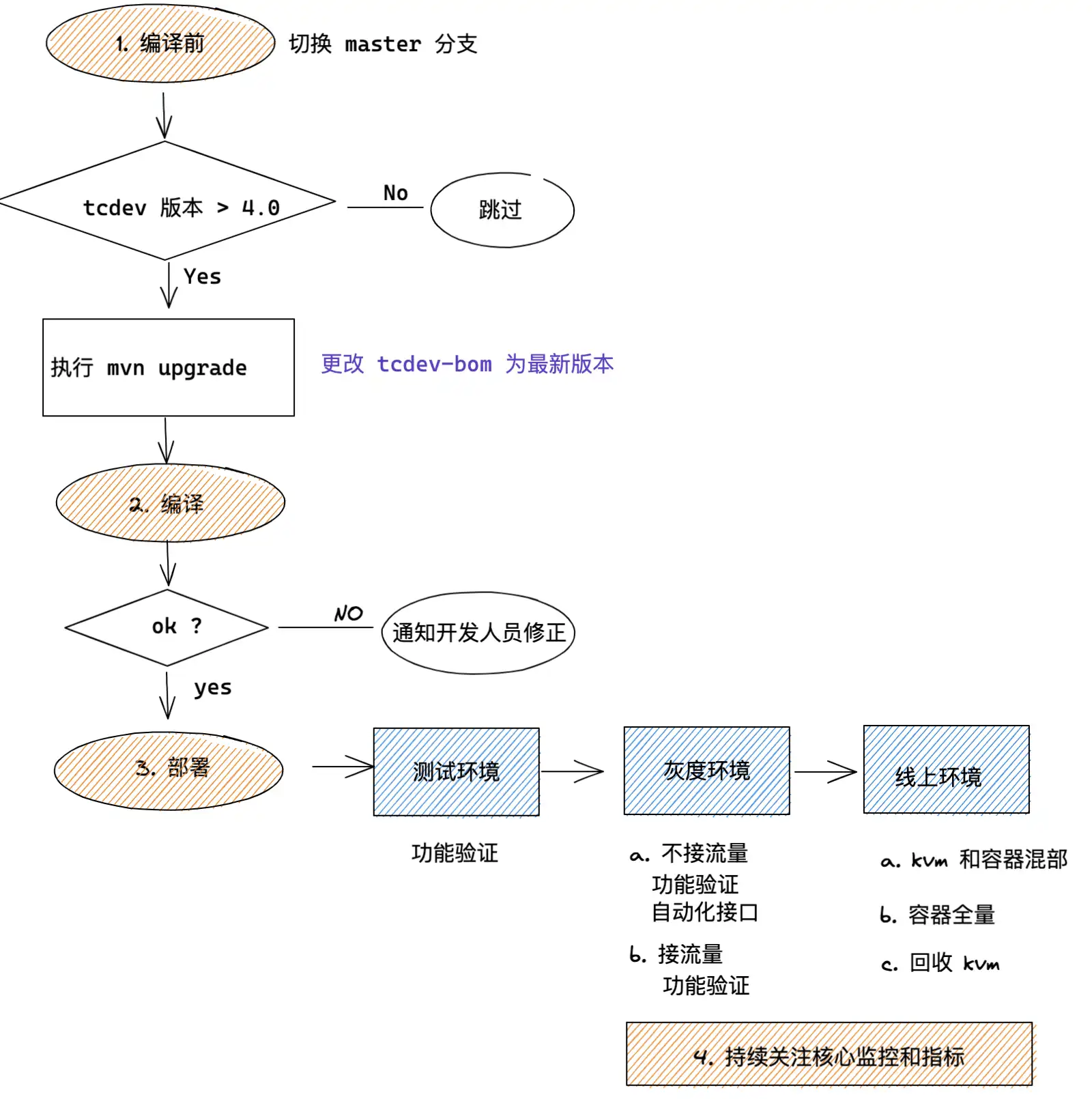
事后复盘的时候,很多业务同学也都反馈这个自助升级迁移的方式为他们节省了大量时间,价值非常明显,得到了大家的认可。
总结
在云原生转型的过程中,如何让业务更顺畅的享受到云原生的红利是非常有挑战的,希望这篇文章能给刚步入云原生的同学带来一些启发。云原生的路上,我们一起共勉!
目录
