






去哪儿网(Qunar.com)
去哪儿网(Qunar.com)是中国领先的在线旅游平台,创立于 2005 年 5 月,总部位于北京。
-
行业
旅游业
-
地点
中国
-
云类型
私有云
-
挑战
多集群管理
-
采用功能
多集群管理, 事件管理
-
公司简介
去哪儿网(Qunar.com)是中国领先的在线旅游平台,创立于 2005 年 5 月,总部位于北京。去哪儿网通过网站及移动客户端的全平台覆盖,以自有技术为驱动,随时随地的为旅游服务供应商和旅行者提供专业的产品与服务。
-
背景
近几年,云原生和容器技术非常火爆,且日趋成熟,众多企业慢慢开始容器化建设,并在云原生技术方向上不断的探索和实践。基于这个大的趋势, 2020 年底 Qunar 也向云原生迈出了第一步——容器化。
云原生是一系列可以为业务赋能的技术架构准则,遵循它可以使应用具有扩展性、伸缩性、移植性、韧性等特点。云原生也是下一代技术栈的必选项,它可以让业务更敏捷。通过实践 DevOps、微服务、容器化、可观测性、反脆弱性(chaos engineering)、ServiceMesh、Serverless 等云原生技术栈,我们便可以享受到云原生带来的技术红利。
-
Qunar 容器化发展时间线
一项新技术要在企业内部落地从来都不是一蹴而就的,Qunar 的容器化落地也同样如此。Qunar 的容器后落地主要经历了 4 个时间节点:
2014 - 2015:业务线同学开始尝试通过 Docker、Docker-Compose 来解决联调环境搭建困难的问题,不过由于 Docker-Compose 的编排能力有限、无法解决真实的环境问题,因此容器化最后也没有推行起来。
2015 - 2017:ops 团队把为了提高 ELK 集群的运维效率,把 ES 集群迁移到了 Mesos 平台上。后来随着 K8s 生态的成熟,把 ES 集群从 Mesos 迁移到了 K8s 平台,运维效率得到了进一步的提升。
2018 - 2019:在业务需求不断增加的过程中,业务对测试环境的交付速度和质量有了更高的要求,为了解决 MySQL 的交付效率问题(并发量大时,网络 IO 成为了瓶颈,导致单个实例交付时长在分钟级),为了解这个问题,我们把 MySQL 容器化,通过 Docker on host 的模式可以在 10 秒之内就可以交付一个 MySQL 实例。
2020 - 2021:云原生技术已经非常成熟了,Qunar 也决定通过拥抱云原生来为业务增加势能。在各个团队齐心协力的努力下,300+ 的 P1、P2 应用已经完成了容器化,并且计划在 2021 年年底全部业务应用实现容器化。
-
落地过程与实践
容器化整体方案介绍
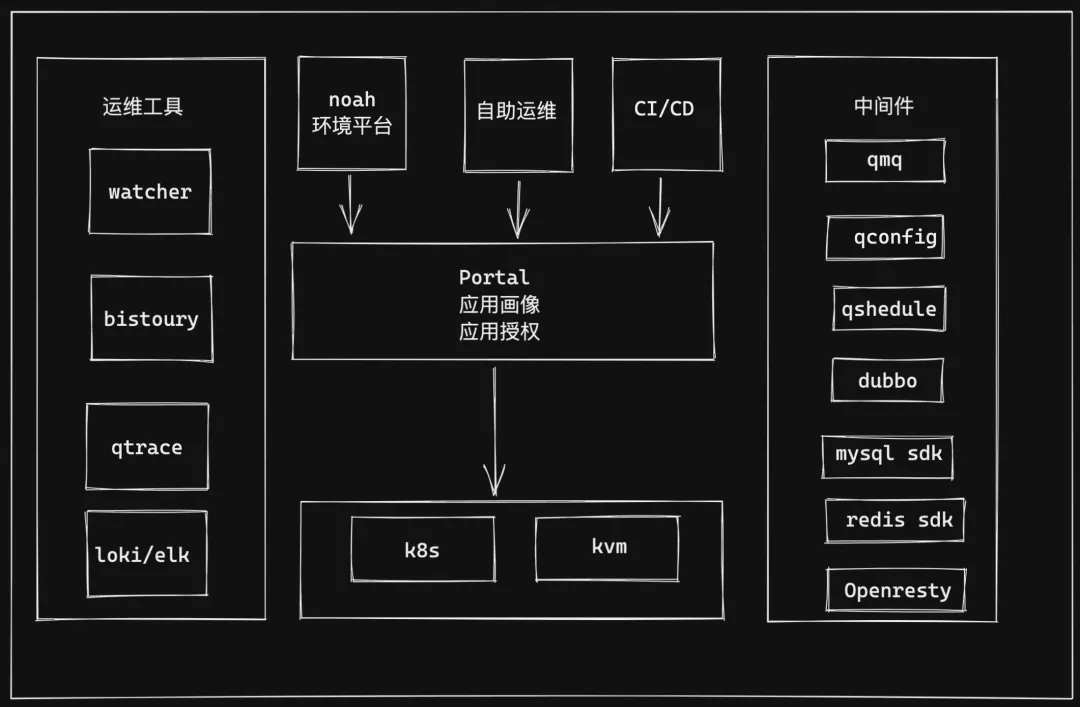
Qunar 在做容器化过程中,各个系统 Portal 平台、中间件、ops 基础设施、监控等都做了相应的适配改造,改造后的架构矩阵如下图所示。
Portal:Qunar 的 PaaS 平台入口,提供 CI/CD 能力、资源管理、自助运维、应用画像、应用授权(db 授权、支付授权、应用间授权)等功能。
运维工具:提供应用的可观测性工具, 包括 watcher(监控和报警)、bistoury(Java 应用在线 Debug)、qtrace(tracing 系统)、loki/elk(0.提供实时日志/离线日志查看)。
中间件:应用用到的所有中间件,mq、配置中心、分布式调度系统 qschedule、dubbo 、mysql sdk 等。
虚拟化集群:底层的 K8s 和 OpenStack 集群。
Noah:测试环境管理平台,支持应用 KVM/容器混合部署。
-
CI/CD 流程改造
主要改造点如下,下方图分别为改造前和改造后。
1. 应用画像:把应用相关的运行时配置、白名单配置、发布参数等收敛到一起,为容器发布提供统一的声明式配置。
2. 授权系统:应用所有的授权操作都通过一个入口进行,并实现自动化的授权。
3. K8s 多集群方案:通过调研对比,KubeSphere 对运维优化、压测评估后也满足我们对性能的要求,最终我们选取了 KubeSphere 作为多集群方案。

-
中间件适配改造
改造关注点:由于容器化后,IP 经常变化是常态,所以各个公共组件和中间件要适配和接受这种变化。

-
应用平滑迁移方案设计
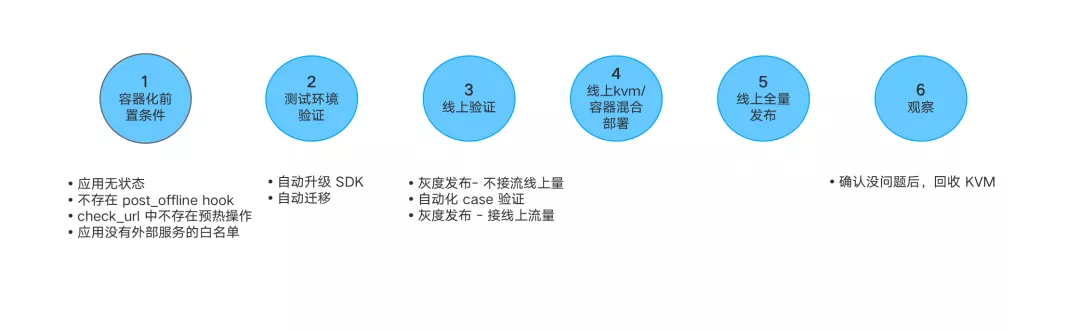
为了帮助业务快速平滑地迁移到容器,我们制定了一些规范和自动化测试验证等操作来实现这个目标。
1. 容器化的前置条件:应用无状态、不存在 post_offline hook(服务下线后执行的脚本)、check_url 中不存在预热操作。
2. 测试环境验证:自动升级 SDK、自动迁移。我们会在编译阶段帮助业务自动升级和更改 pom 文件来完成 SDK 的升级,并在测试环境部署和验证,如果升级失败会通知用户并提示。
3. 线上验证:第一步线上发布,但不接线上流量,然后通过自动化测试验证,验证通过后接入线上流量。
4. 线上 KVM 与容器混部署:保险起见,线上的容器和 KVM 会同时在线一段时间,等验证期过后再逐步下线 KVM。
5. 线上全量发布:确认服务没问题后,下线 KVM。
6. 观察:观察一段时间,如果没有问题则回收 KVM。
-
-
提升多集群管理便捷性
-
提高运维人员效率
-
保障业务数据安全性
-
-
容器化落地过程中碰到的问题
如何兼容过去 KVM 的使用方式,并支持 preStart、preOnline hook 自定义脚本?
KVM 场景中 hook 脚本使用场景介绍:preStart hook——用户在这个脚本中会自定义命令,比如环境准备;preOnline hook——用户会定义一些数据预热操作等,这个动作需要在应用 checkurl 通过并且接入流量前执行。
问题点:K8s 原生只提供了 preStop、postStart 2 种 hook, 它们的执行时机没有满足上述 2 个 KVM 场景下业务用到的 hook。
分析与解决过程:
preStart hook:在 entrypoint 中注入 preStart hook 阶段,容器启动过程中发现有自定义的 preStart 脚本则执行该脚本,至于这个脚本的位置目前规范是定义在代码指定目录下。
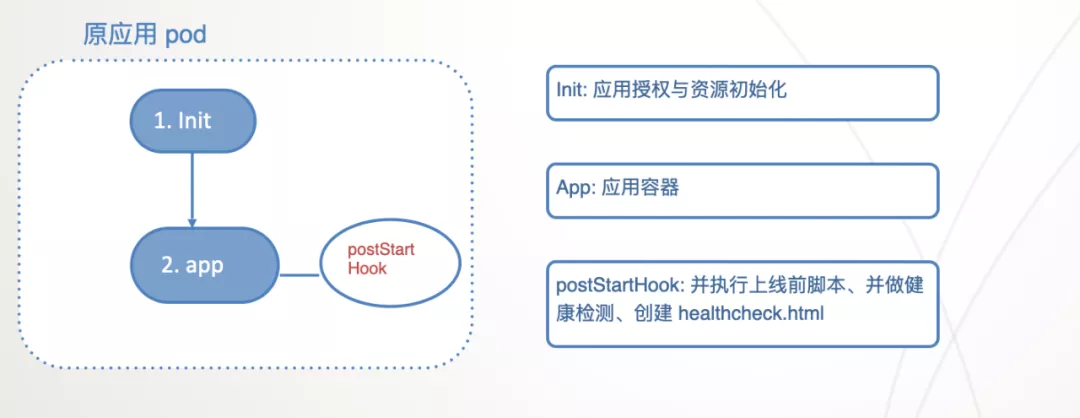
preOnline hook:由于 preOnline 脚本执行时机是在应用 checkurl 通过后,而应用容器是单进程,所以在应用容器中执行这个是行不通的。而 postStart hook 的设计就是异步的,与应用容器的启动也是解耦的, 所以我们初步的方案选择了 postStart hook 做这个事情。实施方案是 postStart hook 执行后会不断轮询应用的健康状态,如果健康检测 checkurl 通过了, 则执行 preOnline 脚本。脚本成功后则进行上线操作, 即在应用目录下创建 healthcheck.html 文件,OpenResty 和中间件发现这个文件后就会把流量接入到这个实例中。
按照上面的方案,Pod 的组成设计如下:
-
发布过程读不到标准输入输出
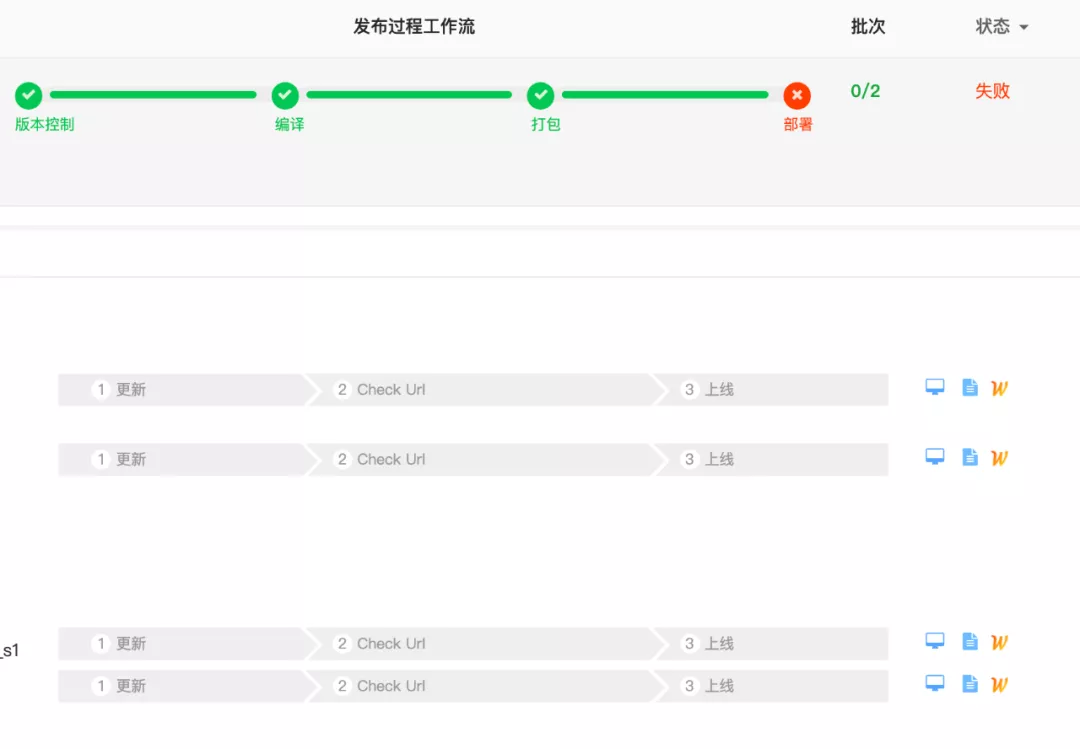
场景介绍:在容器发布过程中如果应用启动失败,我们通过 K8s API 是拿不到实时的标准输入输出流,只能等到发布设置的超时阈值,这个过程中发布人员心里是很焦急的,因为不确定发生了什么。如下图所示,部署过程中应用的更新工作流中什么都看不到。
-
问题点:K8s API 为什么拿不到标准输入输出?
分析与解决过程:
通过 kubectl logs 查看当时的 Pod 日志,什么都没有拿到,超时时间过后才拿到。说明问题不在程序本身,而是在 K8s 的机制上;查看 postStart Hook 的相关文档,有一段介绍提到了 postHook 如果执行时间长或者 hang 住,容器的状态也会 hang 住,不会进入 running 状态, 看到这条信息,大概猜测到罪魁祸首就是这个 postStart hook 了。

-
基于上面的猜测,把 postStart hook 去掉后测试,应用容器的标准输入可以实时拿到了。
找到问题后,解决方法也就简单了,把 postStart hook 中实现的功能放到 Sidecar 中就可以解决。至于 Sidecar 如何在应用容器的目录中创建 healthcheck.html 文件,就需要用到共享卷了。新的方案设计如下:
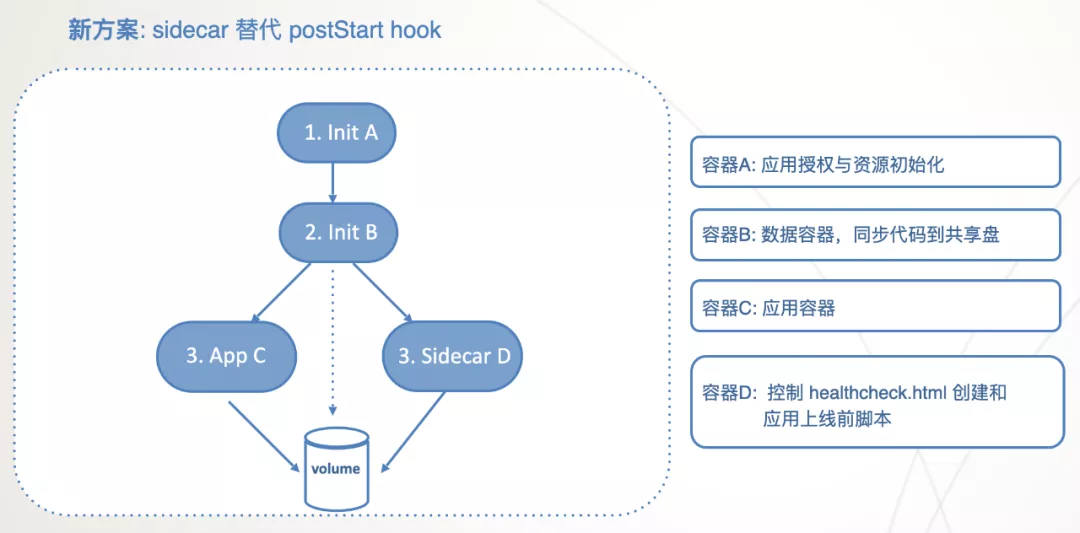
-
使用上述方案后,发布流程的标准输入输出、自定义 hook 脚本的输出、Pod 事件等都是实时可见的了, 发布过程更透明了。
-
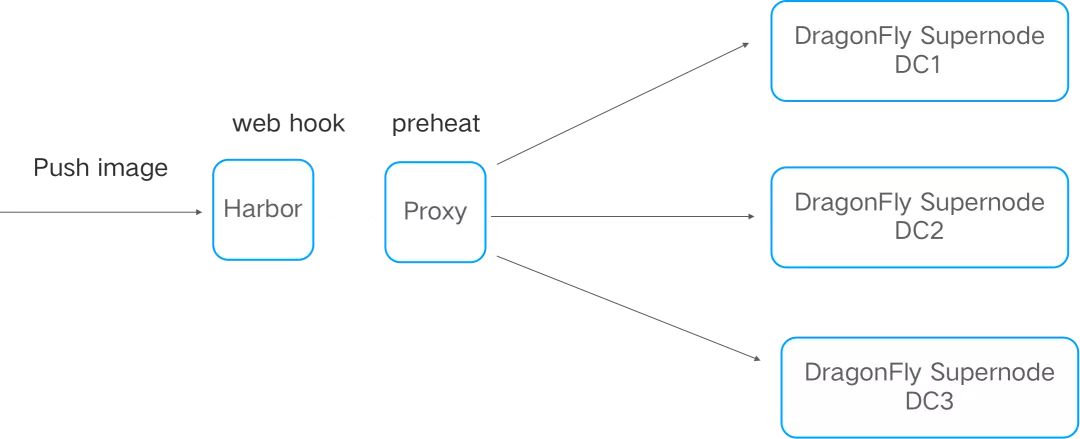
并发拉取镜像超时
场景介绍:我们的应用是多机房多集群部署的,当一个应用的新版本发布时,由于应用的实例数较多,有 50+ 个并发从 harbor 拉取镜像时,其中一些任务收到了镜像拉取超时的报错信息,进而导致整个发布任务失败。超时时间是 kubelet 默认设置的 1 分钟。
分析与解决:
通过排查最终确认是 harbor 在并发拉取镜像时存在性能问题,我们采取的优化方案是通用的 p2p 方案,DragonFly + Harbor。
-
并发大时授权接口抗不住
场景介绍:应用发布过程中调用授权接口失败,K8s 的自愈机制会不断重建容器并重新授权,并发量比较大,最终把授权服务拖垮。
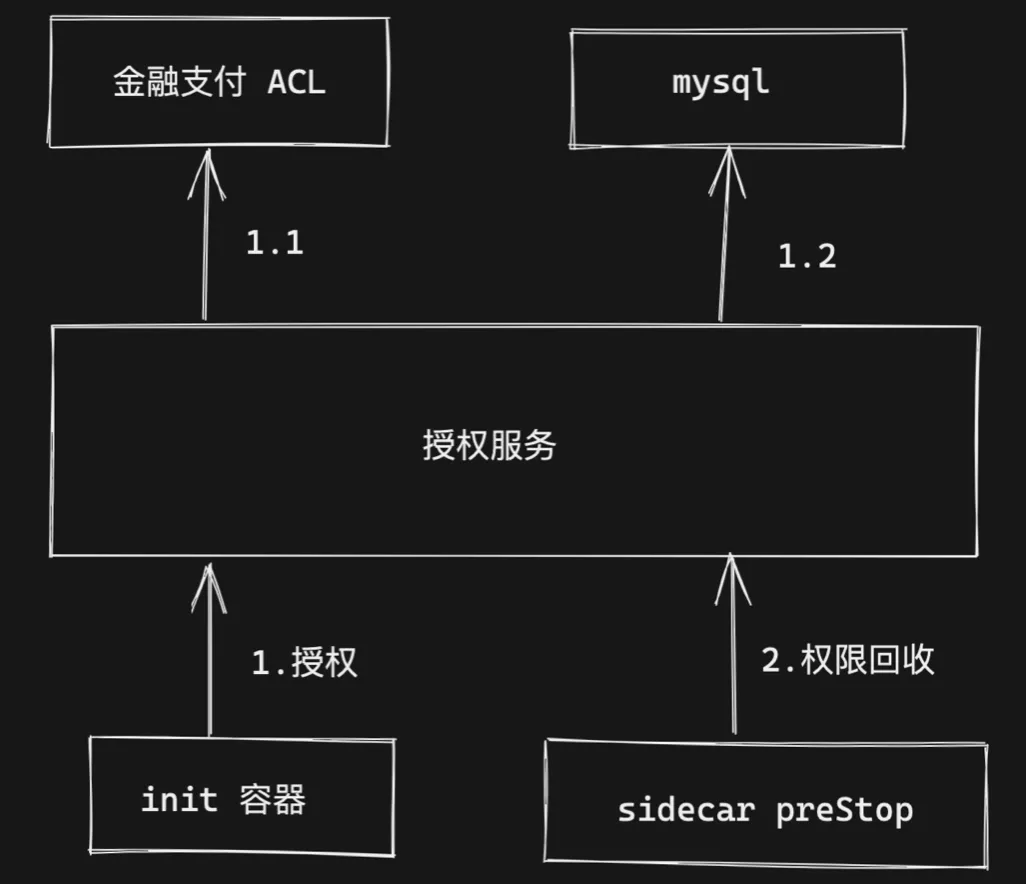
我们的容器授权方案如下:
1. Pod init 容器启动时进行调研授权接口进行授权操作,包括 ACL 和 mysql 的白名单。
2. 容器销毁时会执行 Sidecar 容器的 preStop hook 中执行权限回收操作。
-
问题点:ACL 授权接口涉及到了防火墙,QPS 比较低,大量容器进行 ACL 授权时把服务拖垮。
分析与解决过程:
为了解决上述的问题,限量和降低授权接口调用次数是有效的解决方式。我们采取了下面几个措施:init 容器中的重试次数限制为 1 次;授权接口按应用和 IP 限流, 超过 3 次则直接返回失败,不会再进行授权操作;ACL 中涉及的一些通用的端口,我们统一做了白名单,应用无需再进行授权操作。
-
Java 应用在容器场景下如何支持远程 Debug
KVM 场景 Debug 介绍:在开发 Java 应用的过程中,通过远程 Debug 可以快速排查定位问题,因此是开发人员必不可少的一个功能。Debug 具体流程:开发人员在 Noah 环境管理平台的界面点击开启 Debug, Noah 会自动为该 Java 应用配置上 Debug 选项,-Xdebug -Xrunjdwp:transport=dt_socket, server=y, suspend=n, address=127.0.0.1:50005,并重启该 Java 应用,之后开发人员就可以在 IDE 中配置远程 Debug 并进入调试模式了。
-
容器场景的 Debug 方案:测试环境的 Java 应用默认开启 Debug 模式,这样也避免了更改 Debug 重建 Pod 的过程,速度从 KVM 的分钟级到现在的秒级。当用户想开启 Debug 时,Noah 会调用 K8s exec 接口执行 socat 相关命令进行端口映射转发,让开发人员可以通过 socat 开的代理连接到 Java 应用的 Debug 端口。
问题点:容器场景下在用户 Debug 过程中,当请求走到了设置的断点后,Debug 功能失效。
分析与解决过程:
1. 复现容器场景下 Debug,观察该 Pod 的各项指标,发现 Debug 功能失效的时候系统收到了一个 liveness probe failed,kill pod 的事件。根据这个事件可以判断出当时 liveness check 失败,应用容器才被 kill 的,应用容器重启代理进程也就随之消失了,Debug 也就失效了。
2. 关于 Debug 过程 checkurl 为什么失败的问题,得到的答案是 Debug 时当请求走到断点时,整个 JVM 是 hang 住的,这个时候任何请求过来也会被 hang 住,当然也包括 checkurl,于是我们也特地在 KVM 场景和容器场景分布做了测试,结果也确实是这样的。
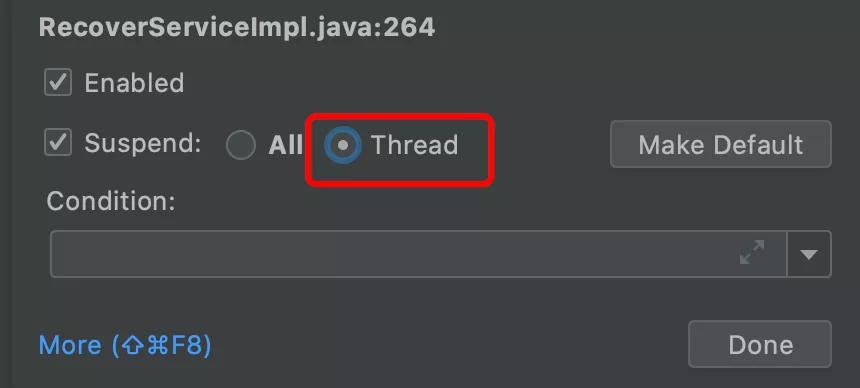
3. 临时解决方案是把断点的阻断级别改为线程级的,这样就不会阻断 checkurl 了, idea 中默认的选项是 Suspend All,改为 Suspend Thread 即可。不过这个也不是最优解,因为这个需要用户手工配置阻断级别,有认知学习成本。
-
4. 回到最初的问题上,为什么容器场景下遇到这个问题,而 KVM 没有,主要是因为容器场景 K8s 提供了自愈能力,K8s 会定时执行 liveness check, 当失败次数达到指定的阈值时,K8s 会 kill 掉容器并重新拉起一个新的容器。
5. 那我们只好从 K8s 的 liveness 探针上着手了,探针默认支持 exec、tcp 、httpGet 3 种模式,当前使用的是 httpGet,这种方式只支持一个 url, 无法满足这个场景需求。经过组内讨论, 最后大家决定用这个表达式 (checkurl == 200) || (socat process && java process alive) 在作为应用的 liveness 检测方式,当 Debug 走到断点的时候, 应用容器就不会阻断了, 完美的解决了这个问题。
以上就是我们落地容器化过程中遇到的几个问题与我们的解决思路。其中很重要的一点是从 KVM 迁移到容器时需要考虑用户的使用习惯、历史功能兼容等要点,要做好兼容和取舍,只有这样容器化落地才会更顺畅。
-
使用 KubeSphere 作为多 K8s 集群管理平台,大大提高了运维同学的工作效率,同时作为统一的集群入口,它也保障了业务数据的安全。
去哪儿网

-
未来展望
多集群稳定性治理:让可观测性数据更全面、覆盖度更广,进而完善我们的 APM 系统,提升排查问题效率;通过实施混沌工程来验证、发现和消除容器化场景的稳定性盲区。
提高资源利用率:根据业务指标实现弹性扩缩容;根据应用的历史数据智能的调整 requests。
ServiceMesh 方案落地:我们是基于 Istio 和 MOSN 以及当前的基础架构做的 mesh 方案,目前在测试阶段,这套方案落地后相信会让基础架构更敏捷。
