






SegmentFault 思否
SegmentFault 思否是国内领先的新一代开发者社区和技术媒体,也是中国最大的 Hackathon 组织者,目前已经覆盖和服务了上千万中国软件开发者和 IT 信息从业者。
-
行业
技术社区
-
地点
中国
-
云类型
公有云
-
挑战
人员、运营成本、自动化脚本效率低
-
采用功能
DevOps、CI/CD
-
公司简介
SegmentFault(https://segmentfault.com/)是一家综合性技术社区,由于它的内容跟编程技术紧密相关,因此访问量的波动也和这一群体的作息时间深度绑定。通常情况下 web 页面的请求量峰值在 800 QPS 左右,但我们还做了前后端分离,所以 API 网关的峰值 QPS 是请求量峰值的好几倍。
-
架构历史
2012 年,为了帮助中文开发者用母语在像 StackOverflow 这样的网站上提问,SegmentFault 诞生。但是第一个版本非常简陋,访问量很少。将它放在了国外的 VPS 托管商 Linode 上,所有的应用、数据库、缓存都挤在一个实例上。
2013-2014 年,我们选择了自己购买二手服务器去机房托管,经常遇到问题,我们团队在外地又去不了机房,只能等管理员去机房帮我们解决。正好在 2014 年我们的网站被 DDos 攻击了,机房为了不连累其他服务器,直接把我们的网线拔掉了。
2014-2019 年,中国的云计算也开始起步了,于是我们把整个网站从物理服务器迁移到了云服务上。当然使用上并没有什么不同,只是把物理机器替换成了虚拟主机。
2020 年至今,随着云原生理念的兴起,我们的业务模式也发生了很大变化,为了让系统架构适应这些变化,我们把网站的主要业务都迁移到了 KubeSphere 上。
-
遇到的挑战
我们遇到了不少挑战,促使我们不得不往 K8s 架构上迁移。
其次,复杂的场景引发了复杂的配置管理,不同的业务要用到不同的服务,不同的版本,即使用自动化脚本效率也不高。
另外,我们内部人员不足,所以没有专职运维,现在 OPS 的工作是由后端开发人员轮值的。但后端开发人员还有自己本职工作要做,所以对我们最理想的场景是能把运维工作全部自动化。
最后也是最重要的一点就是我们要控制成本。当然,如果资金充足,以上的问题都不是问题,但是对于创业公司(特别是像我们这种访问量比较大,但是又不像电商,金融那些盈利的公司)来说,我们必将处于且长期处于这个阶段。因此能否控制好成本,是一个非常重要的问题。
-
前后端分离
2020 年以前,SegmentFault 的网站还是非常传统的后端渲染页面的方法,所以服务端的架构也非常简单。服务端将浏览器的 http 请求转发到后端的 php 服务,php 服务渲染好页面后再返回给浏览器。这种架构用原有的部署方法还能支撑,也就是在各个实例上部署 php 服务,再加一层负载均衡就基本满足需求了。
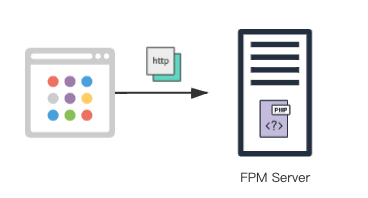
-
然而随着业务的持续发展,后端渲染的方式已经不适合我们的项目规模了,因此我们在 2020 年做了架构调整,准备将前后端分离。前后端分离的技术特点我在这里就不赘述了,这里主要讲它给我们带来了哪些系统架构上的挑战。一个是入口增多,因为前后端分离不仅涉及到客户端渲染(CSR),还涉及到服务端渲染(SSR),所以响应请求的服务就从单一的服务变成了两类服务,一类是基于 node.js 的 react server 服务(用来做服务端渲染),另一类是 基于 php 写的 API 服务(用来给客户端渲染提供数据)。而服务端渲染本身还要调用 API,而我们为了优化服务端渲染的连接和请求响应速度,还专门启用了了使用专有通讯协议的内部 API 服务。
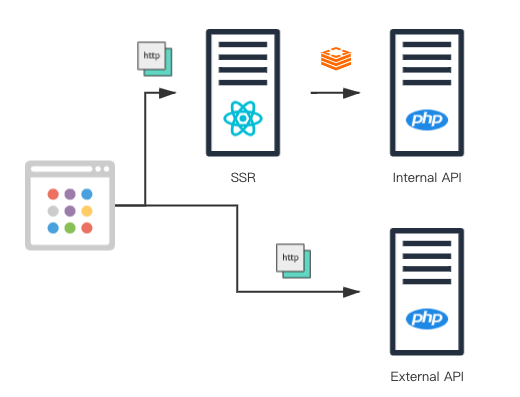
-
所以实际上我们的 WEB SERVER 有三类服务,每种服务的环境各不相同,所需的资源不同,协议不同,各自之间可能还有相互连接的关系,还需要负载均衡来保障高可用。在快速迭代的开发节奏下,使用传统的系统架构很难再去适应这样的结构。
我们迫切需要一种能够快速应用的,方便部署各种异构服务的成熟解决方案。
-
KubeSphere 带来了什么?
开箱即用
首先是开箱即用,理论上来说这应该是 KubeSphere 的优点,我们直接点一点鼠标就可以打造一个高可用的 K8s 集群。这一点对我们这种没有专职运维的中小团队来说很重要。根据我的亲身经历,要从零开始搭建一个高可用的 K8s 集群还是有点门槛的,没有接触过这方面的运维人员,一时半会是搞不定的,其中的坑也非常多。
如果云厂商能提供这种服务是最好的,我们不用在服务搭建与系统优化上花费太多时间,可以把更多的精力放到业务上去。之前我们还自己搭建数据库,缓存,搜索集群,后来全部都使用云服务了。这也让我们的观念有了转变,云时代的基础服务,应该把它视为基础设施的一部分加以利用。

-
用代码管理部署
如果能把运维工作全部用代码来管理,那就再理想不过了。而目前 K8s 确实给我们提供了这样一个能力,现在我们每个项目都有一个 Docker 目录,里面放置了不同环境下的 Dockerfile,K8s 配置文件等等。不同的项目,不同的环境,不同的部署,一切都可以在代码中描述出来加以管理。
比如我们之前提到的同样的 API 服务,使用两种协议,变成了两个服务。在这现在的架构下,就可以实现后端代码一次书写,分开部署。其实这些文件就代替了很多部署操作,我们需要做的只是定义好以后执行命令把它们推送到集群。
而一旦将这些运维工作代码化以后,我们就可以利用现有的代码管理工具,像写代码一样来调整线上服务。更关键的一点是,代码化之后无形中又增加了版本管理功能,这离我们理想中的全自动化运维又更近了一步。
-
持续集成,快速迭代
持续集成标准化了代码发布流程,如果能将持续集成和 K8s 的部署能力结合起来,无疑能大大加快项目迭代速度。而在使用 K8s 之前我们就一直用 GitLab 作为版本管理工具,它的持续集成功能对我们来说也比较适用。在做了一些脚本改造之后,我们发现它也能很好地服务于现有的 K8s 架构,所以也没有使用 K8s 上诸如 Jenkins 这样的服务来做持续集成。
步骤其实也很简单,做好安全配置就没什么问题。我们本地跑完单元测试之后,会自动上线到本地的测试环境。在代码合并到上线分支后,由管理员点击确认进行上线步骤。然后在本地 build 一个镜像推送到镜像服务器,通知 K8s 集群去拉取这个镜像执行上线,最后执行一个脚本来检查上线结果。整个流程都是可视化可追踪的,而且在代码管理界面就可以完成,方便开发者查看上线进度。

-
-
开箱即用的特性大大降低了企业容器化的使用门槛
-
更加精细地控制服务资源粒度,降低企业运营成本
-
实现全自动化测试部署,大大提高了发布效率
-
-
总结经验
管理好基础镜像
目前我们用一个专门的仓库来管理这些基础镜像,这可以使开发人员拥有与线上一致的开发环境,而且后续的版本升级也可以在基础镜像中统一完成。
除了将 Dockerfile 文件统一管理以外,我们还将镜像 build 服务与持续集成结合起来。每个 Dockerfile 文件都有一个所属的 VERSION 文件,每次修改里面的版本号并提交,系统都会自动 build 一个相应的镜像并推送到仓库。基础镜像的管理工作完全自动化了,大大减少了人为操作带来的错误与混乱。
-
KubeSphere 使用
别把日志服务放到集群里。这一点在 KubeSphere 文档中就有提及。具体到日志服务,主要就是一个 Elastic 搜索服务,自建一个Elastic 集群即可。因为日志服务本身负载比较大,而且对硬盘的持续性需求高,如果你会发现日志服务本身就占据了集群里相当大的资源,就得不偿失了。
如果生产环境要保证高可用,还是要部署 3 个或以上的节点。从我们使用的经验来看,主节点偶尔会出现问题。特别是遇到节点机器要维护或者升级的时候,多个主节点可以保证业务的正常运行。
如果你本身不是专门提供数据库或缓存的服务商,这类高可用服务就不要上K8s,因为要保证这类服务高可用本身就要耗费你大量的精力。我建议还是尽量用云厂商的服务。
副本的规模和集群的规模要匹配。如果你的容器只有几个节点,但一个服务里面扩展了上百个副本,系统的调度会过于频繁从而把资源耗尽。所以这两者要相匹配,在系统设计的时候就要考虑到。
-
KubeSphere 的应用改变了我们的整个开发流程,它让运维工作可视化,代码化,标准化。从而使得我们的开发人员可以参与到整个交付流程中去,大大提升了产品发布效率。而得益于 KubeSphere 良好的交互设计,我们还能快速定位和处理线上事故,提高了系统运行的稳定性。
SegmentFault

-
未来展望
随着后端的不断微服务化,我们将越来越依赖 K8s 提供的低成本系统管理能力,而在这之中 KubeSphere 也扮演了越来越重要的角色。当前系统架构的趋势是自动化和标准化,管理系统的手段也将从配置变为代码,这大大增加系统的灵活性和可维护性,而复杂性也随之提升。软件决定了我们看待计算能力的方式,KubeSphere 这类软件带来的新的可能将促使我们不断探索系统架构的新思路。
